
A synthetic experiment: simulating the performance of Sentinel-2¶
A useful application of the EOLDAS tools is to simulate how different sensors or combinations of sensors might be expected to work together. Simply, we could generate a set of artificial observations, acquired by a sensor (or sensors) from which the spectral, noise and orbital acquisition characteristics are known (or we can try different set ups to see their trade offs). We can then use EOLDAS to invert these synthetic observations and compare to the reality that went into them. This type of experiments can be very useful to test, for example, the usefulness of constellation concepts. The current example is a reduced version of the experiments that are presented in Lewis et al (2010), and show the use of EOLDAS in simulating ESA’s upcoming Sentinel-2 performance for the inversion of biophysical parameters. In this document, we try to reproduce the middle column in Figure 2 in Lewis et al (2010)
The experiment can be split into a set of simple tasks:
- We need to generate an appropriate set of observations. On the one hand, this requires
- An idea of typical angular sampling.
- An idea of the statistics of missing observations due to e.g. cloud.
- Trajectories for the land surface parameters.
Forward model the land surface parameters to land surface reflectance.
Add noise to the observations
Invert the observations, with whatever prior information might be available.
The first step will require the definition of a typical re-visit schedule for the sensor, as well as information on illumination geometries. We make use of the pyephem Python package to calculate the solar position at a given latitude and longitude. Some simple rules are given to model the sensor acquisition geometry (for example, the view zenith angle is assumed to be random). We can use full wavebands, or just the median wavelength of each band (the latter is far more efficient, and this solution can be used as a starting point to solve the full bandpass problem).
A further refinement is the inclusion of missing observations due to cloud cover, for example. It is typically observed that cloudiness is correlated in time, so a model of cloudiness that simulates the typical burst nature of cloud statistics is required. Another way to go about this is to use long term cloudiness observations, but we choose a very simple approach in this work.
The parameter trajectories are functions that describe the evolution of a given parameter in time. In this case, we choose to vary the following parameters:
- LAI
- Chlorophyll concentration
- Leaf water
- Leaf dry matter
- Number of leaf layers
- First soil component
This is an ambitious scenario: the analytic trajectories chosen for these parameters are smooth, but with very different degrees of smoothness. Some parameters are set to be constant (leaf layers and leaf dry matter). We will assume that the regulariser that solves this problem is identical for all the parameters, and constant in time. Even though we know that this is not the case, this simplifying assumption still allows the recovery of reasonable parameter estimates. Note that while in some cases (such as leaf area index) one might have mechanistic models that maybe use meteorological inputs to simulate photosynthesis and allocation of assimilated carbon to the leaves to estimate the amount of leaf area, for other parameters that have a significant impact on the remote sensing signal, these models might not be available.
The forward modelling of the parameter trajectories, coupled with the required wavebands and illumination geometries, produces a set of synthetic observations: this is what a sensor, operating with the given characteristics would “see”, in terms of surface reflectance. As with any measurement, noise needs to be incorporated. We do this by adding some Gaussian noise to the simulated reflectances, in line with what we expect to be typical values after atmospheric correction. Although we assume noise to be uncorrelated across bands, in practice it will be.
Finally, we solve the inverse problem: find the parameter trajectories given the set of noisy and incomplete observations. In reality, we also need to estimate the strength of the regularisation, a hyperparameter. In Lewis et al (2011) this is done using cross-validation. In the paper, we proceeded as follows:
Set a number of values that \(\Gamma\) might take. This will necessarily be a large range (say from \(10^{-5}-10^{5}\)), but prior experience might dictate a suitable interval.
For one value of \(\Gamma\)...
Select one single observation, and remove it from the observations that will go into the inversion
- Solve the inverse problem
- Predict the missing observation, and compare with the truth
Calculate a prediction metric, such as root mean square error (RMSE) or similar
Select the value of \(\Gamma\) that results in the most accurate predictions.
This method is clearly very time consuming, but can be carried out in parallel. Note that the optimal value of \(\Gamma\) will be different if the nature of the problem (priors, order of the smoothness constraint, etc) changes. We shall not concern ourselves with crossvalidaiton here, and will use the optimal values from the paper.
For comparison purposes, we will also solve each observation independently, which is similar to what one would do in look-up table-based inversion approaches. In general, the problem of inverting six parameters from a single multispectral observation is incredibly ill-posed. The very informative sampling scheme of the MSI2 sensor however allows inversions. We shall also calculate the associated uncertainty of these single inversions, which we expect to be very high (and exhibit large degrees of correlation between parameters), and also note that when no observations are available, there will be no estimate of land surface parameters.
The next sections describe the python script that performs the experiment.
Anatomy of the simulation code¶
The code is organised in a single class, Sentinel. This class will perform all the above described tasks. The user might want to modify this class to perform other experiments. The class basically writes out files, and also runs the eoldas prototype as required. As mentioned above, we use the pyephem package to simulate the solar geometry.
Generating the synthetic observations¶
The code for this is fairly simple, and can be seen in the main function in sentinel.py:
lad = 1,5
[general]
is_spectral = True
calc_posterior_unc=True
help_calc_posterior_unc="Posterior uncertainty calculations"
write_results=True
doplot=True
We first instantiate the Sentinel class, calculate the parameter temporal trajectories using the Sentinel.parameters method. This requires a time axis as well as an output file (in this case, input/truth.dat. This file can also be used to compare inversion results etc.). Once the parameter trajectories have been established, we can forward model them to surface reflectance using the Sentinel.fwdModel method. This method has a number of options that are important to note:
- ifile
- input data (parameters) file
- ofile
- output reflectance data file
- lat
- latitude (default ‘50:0’) (see ephem)
- lon
- longitude (default ‘‘0:0’) (see ephem)
- year
- as int or string (default ‘2011’)
- maxVza
- maximum view zenith angle assumed (15 degrees default)
- minSD
- minimum noise
- maxSD
- maximum noise. The uncertainty in each waveband is scaled linearly with wavelength between minSD and maxSD
- fullBand
- set True if you want full band pass else False (default False). Note that its much slower to set this True.
- confFile
- configuration file (default config_files/sentinel0.conf). If this file doesnt exist, it will be generated from self.confTxt. If that doesn’t exist, self.generateConfTxt() is invoked to provide a default.
- every
- sample output every ‘every’ doys (default 5)
- prop
- proportion of clear sample days (default 1.0)
- WINDOW
- size of smoothing kernel to induce temporal correlation in data gaps if prop < 1
Note that some other settings (such as default parameter values, and which parameters will be varied temporally) are set in the class constructor. In this case, we run the forward model twice, to create two distinct datasets: a complete best-case scenario, and a second scenario where the missing observations (with a proportion of 0.5 missing observations). These two datafiles are “clean”, i.e., there’s no noise. The Sentinel.addNoiseToObservations adds Gaussian independent noise to the observations. The variance of the noise is estipulated in the header of the clean data file (a linear increase of uncertainty with wavelength).
Solving each data individually¶
This part of the code will solve for each observation individually: assuming some prior knowledge, we solve for the weighted least squares fit. Mathematically, this for each observation \(\mathbf{y}\), we minimise the functional \(J(\mathbf{x})\), where \(\mathbf{x}\) is the state tht describes that observation.
Solving for single observations is a very hard problem: there usually isn’t an unique solution as parameter compensate for each other, and the observational constraint does not have enough information to allow this. This is made even worse by additional noise. In consequence, the shape of \(J(\mathbf{x})\) is very flat over large areas, showing no strong preference for values of the state vector. As a first test, we can use the noise-free synthetic observations and invert them using some kind of gradient descent algorithm that minimises \(J(\mathbf{x})\). To make it faster, we can start the gradient descent algorithm with the true values, and then calculate the Hessian and its inverse and look at uncertainties in retrieved parameters. This is quite instructive in its own right. A second test would be start the minimisation at some other point that it’s not the true state, and see how the solution compares. Finally, we’d want to invert each individual observation, taking into account the noise.
We test some of these ideas with the clean datasets (those that have had no noise added to them). We also plot the results using graphical methods Sentinel.crossPlot and Sentinel.paramPlot.
plotmod=30
help_plotmod='frequency of plotting'
plotmovie=False
epsilon=10e-15
help_epsilon="Epsilon"
[general.optimisation]
randomise=False
[operator]
prior.name=Operator
prior.datatypes = x,y
obs.name=Observation_Operator
obs.datatypes = x,y
[operator.prior.x]
names = $parameter.names[1:]
datatype = x
[operator.prior.y]
control = 'mask'.split()
names = $parameter.names[1:]
sd = [10.0]*len($operator.prior.y.names)
help_sd='set the prior sd'
datatype = y
state = $parameter.x.default[1:]
help_state = "Set the prior state vector"
[operator.prior.y.result]
filename='output/rse1/rse1_test_prior.dat'
help_filename = 'prior filename'
[operator.obs.rt_model]
model=semidiscrete1
use_median=True
help_use_median = "Flag to state whether full bandpass function should be used or not. If True, then the median wavelength of the bandpass function is used"
bounds = [400,2500,1]
help_bounds = "The spectral bounds (min,max,step) for the operator'
ignore_derivative=False
help_ignore_derivative = "Set to True to override loading any defined derivative functions in the library and use numerical approximations instead"
[operator.obs.x]
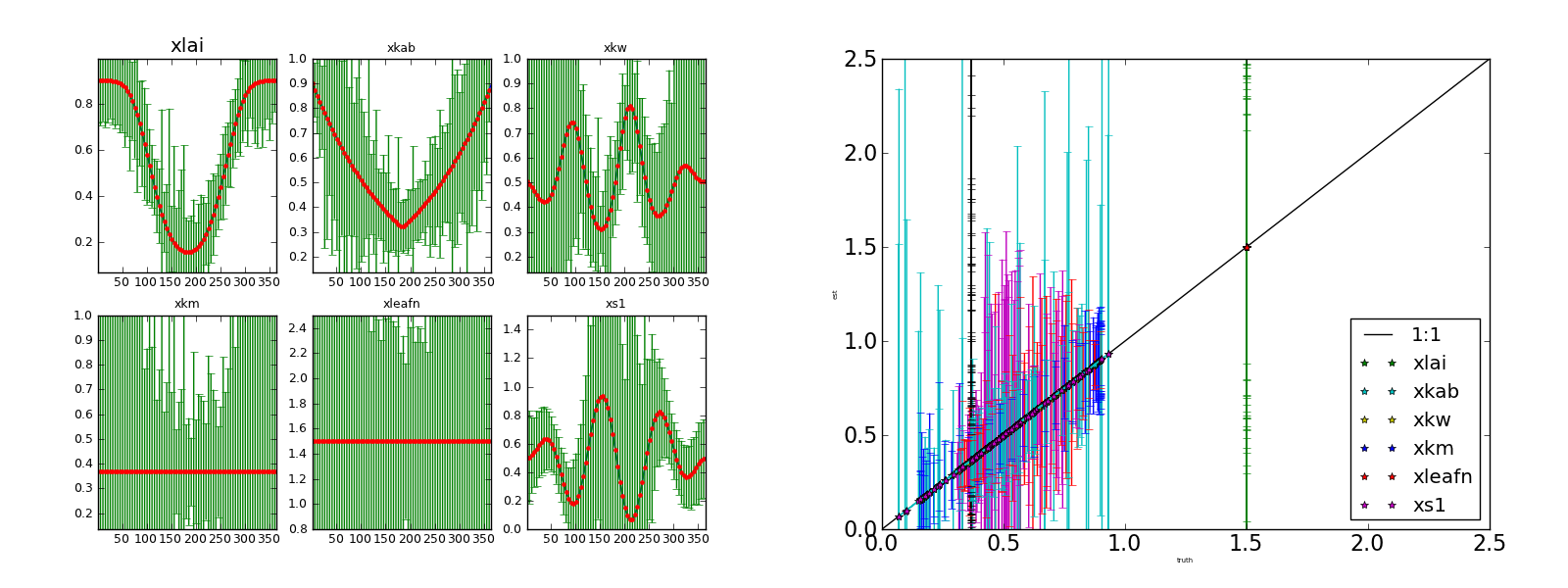
Inverting each individual observation (no noise) starting from the true solution. Left panel: (transformed) parameters and 95% CI Right panel: scatterplot of retrieved parameters vs true parameters.
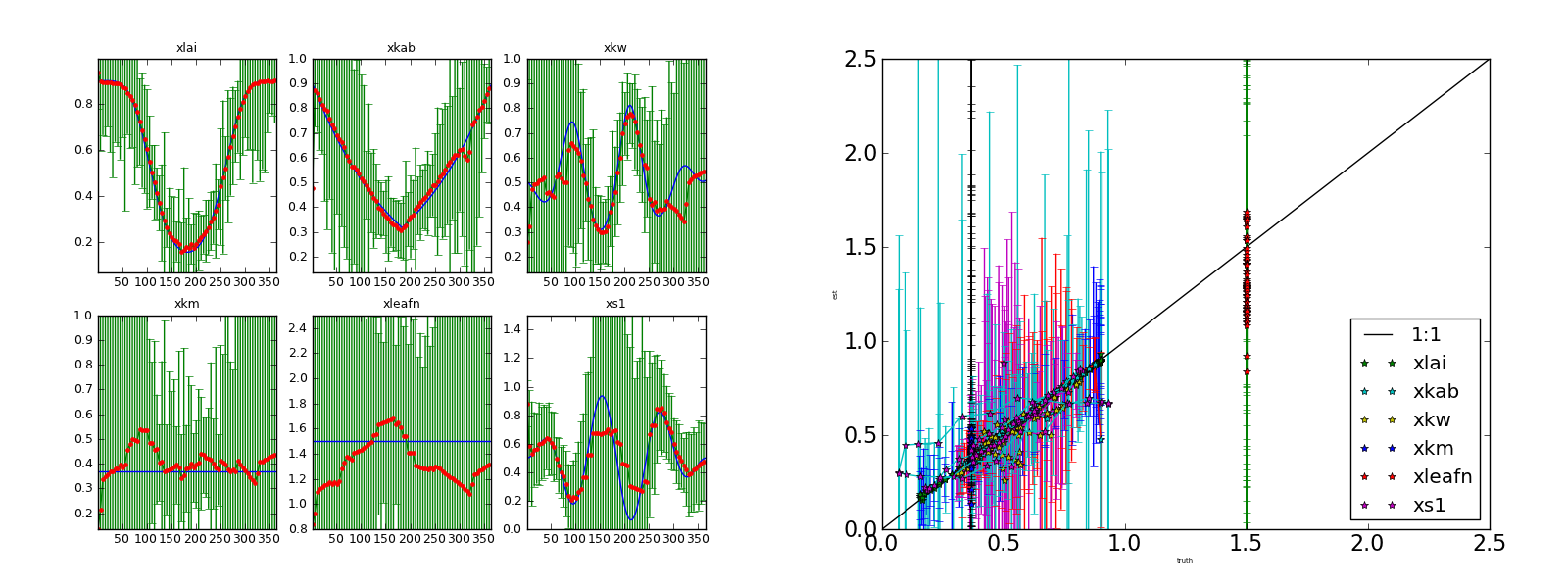
Inverting each individual observation (no noise) not specifying the true solution. Left panel: (transformed) parameters and 95% CI Right panel: scatterplot of retrieved parameters vs true parameters.
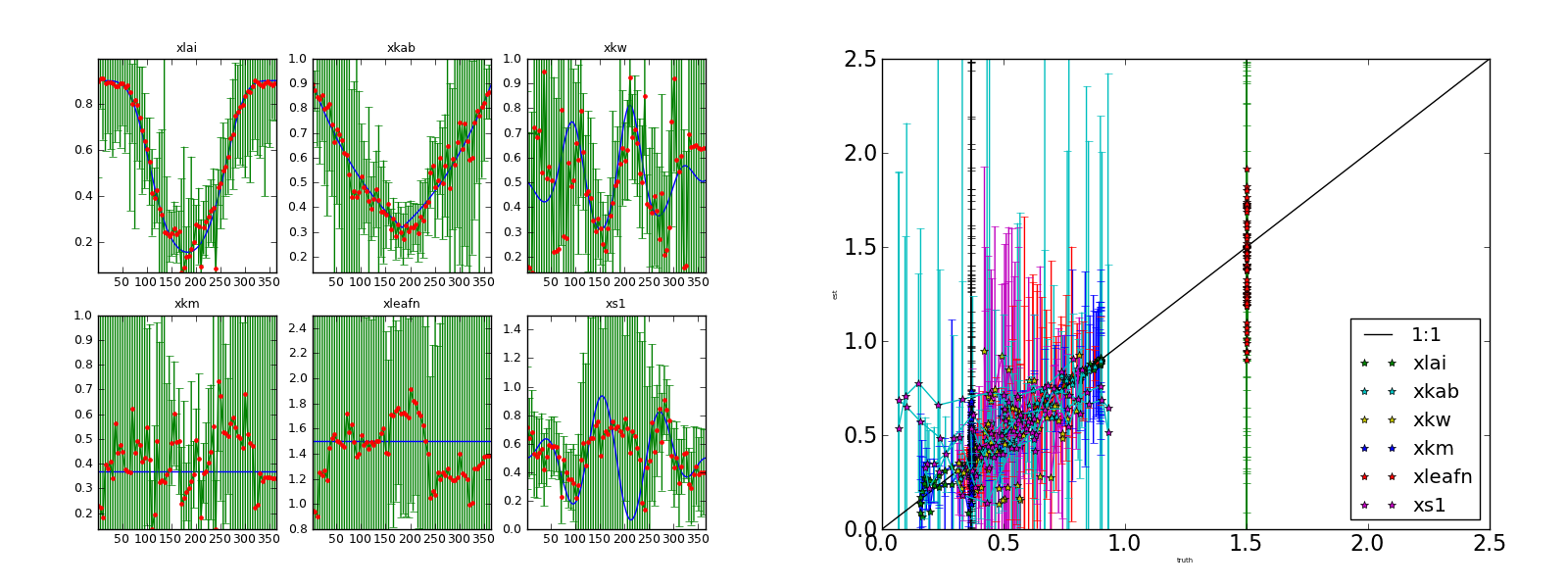
Inverting each individual noisy observation starting from the true solution. Complete series. Left panel: (transformed) parameters and 95% CI Right panel: scatterplot of retrieved parameters vs true parameters.
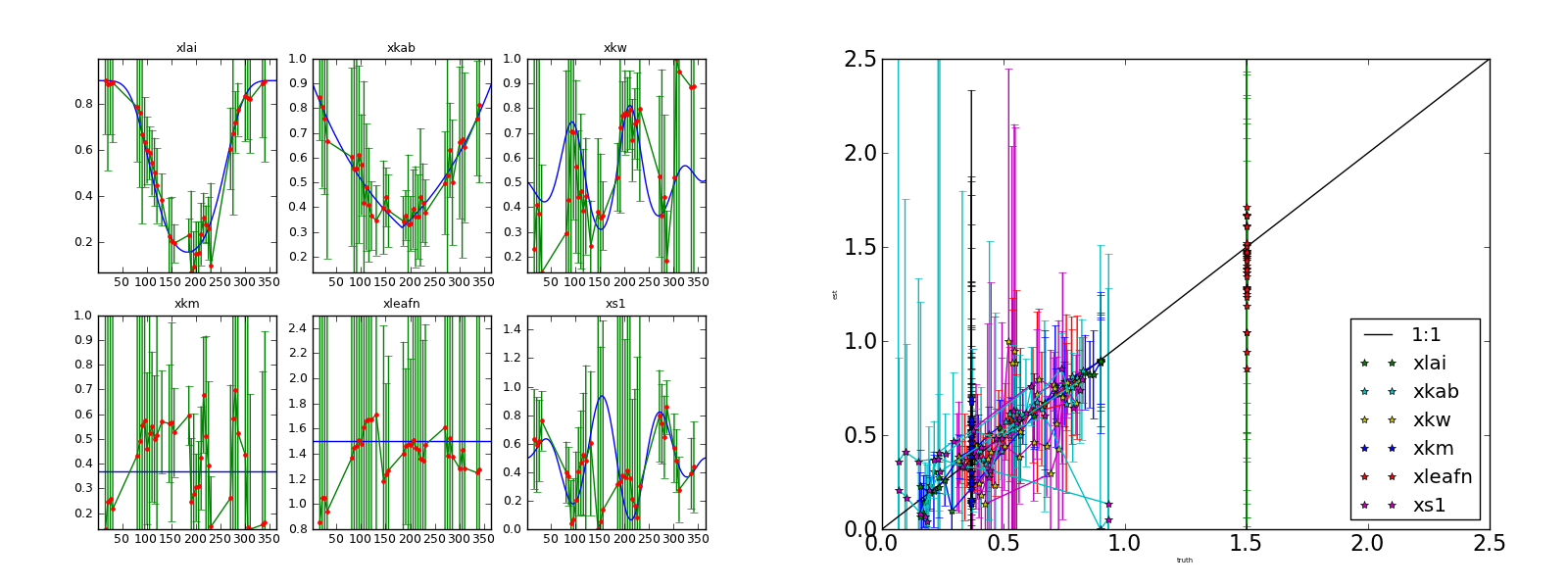
Inverting each individual noisy observation starting from the true solution. Gappy series. Left panel: (transformed) parameters and 95% CI Right panel: scatterplot of retrieved parameters vs true parameters.
Solving using data assimilation¶
Finally, we can solve the problem using the DA framework. This is done using the Sentinel.solveRegular method. One way to speed up processing is to start the inversion with the results calculated above for the single observations.
sd = [1.0]*len($operator.obs.x.names)
datatype = x
[operator.obs.y]
control = 'mask vza vaa sza saa'.split()
names = ['433-453','457.5-522.5','542.5-577.5','650-680','697.5-712.5','732.5-747.5','773-793','784.5-899.5','855-875','935-955','1565-1655','2100-2280']
sd = ["0.004", "0.00416142", "0.00440183", "0.00476245", "0.00489983", "0.00502003","0.00516772", "0.00537035", "0.00544934", "0.0057241", "0.00800801","0.01" ]
datatype = y
state = 'data/rse1_test.100.dat'
help_state='set the obs state file'
[operator.obs.y.result]
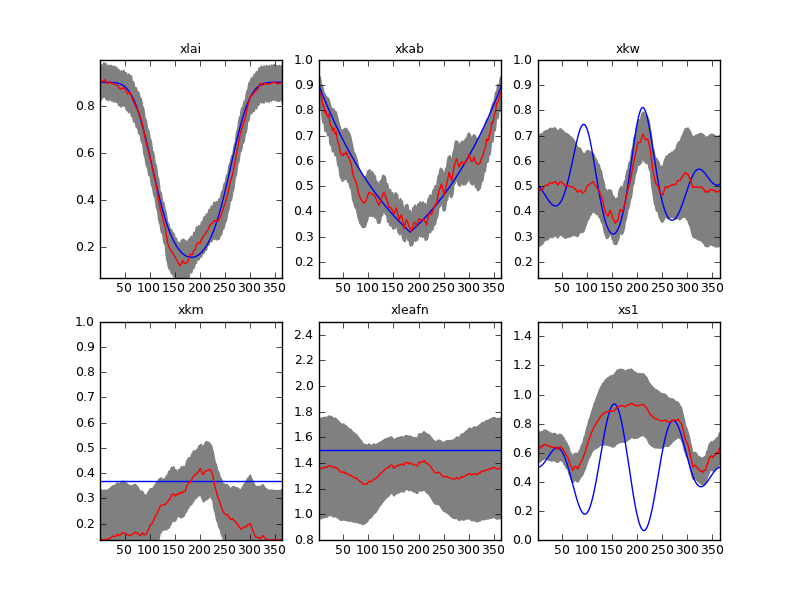
Result of inverting the sentinel synthetic experiments with a first order differential operator. Complete time series and \(\Gamma=37\).
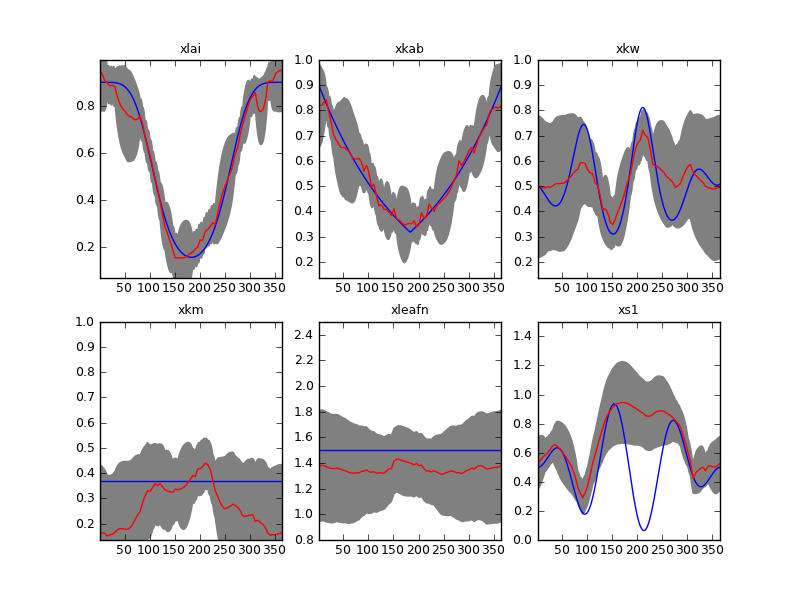
Result of inverting the sentinel synthetic experiments with a first order differential operator. Gappy time series and \(\Gamma=37\).
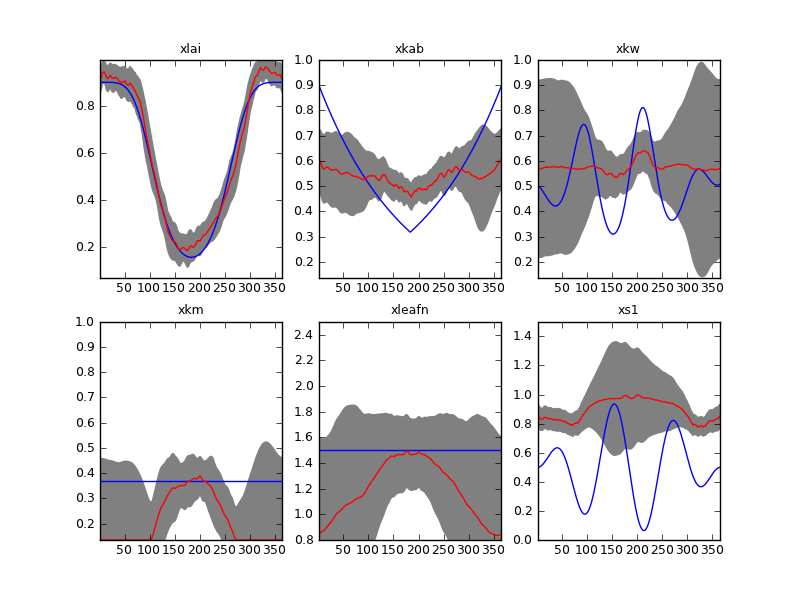
Result of inverting the sentinel synthetic experiments with a second order differential operator. Complete time series and \(\Gamma=175\).
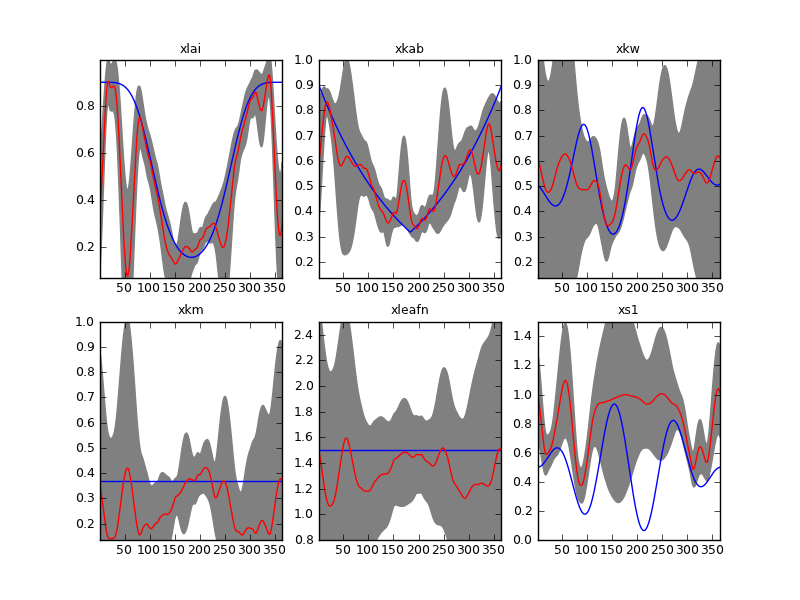
Result of inverting the sentinel synthetic experiments with a second order differential operator. Gappy time series and \(\Gamma=175\).