RideLondon data download
So a quick post on how to get access the web-based data on rider timings for the RideLondon event. The idea is that you can access the cyclist timings, and then maybe do some statistics (or boost/depress your morale by looking at how your time compares to the wider population taking part in the event!).
Pre-requisites
We'll be using requests and BeautifulSoup to access the website and extract the data. You can install them easily by
pip install requests pip install beautifulsoup4
or the may already be installed on your system.
from bs4 import BeautifulSoup
import requests
import numpy as np
import matplotlib.pyplot as plt
In fact, you don't even need requests, as good old urllib2 will work as well. Also, since we are not doing any complicated parsing, it's likely that you could also forego BeautifulSoup and just use a couple of regular expressions!
The rationale
The rationales of this is to access the database rider by rider, using the rider number as the unique rider indicator. To this end, we need to concoct the individual URL for each rider. This is given by http://results.prudentialridelondon.co.uk/2013/?num_results=100&pid=search&search%5Bstart_no%5D=RIDER_ID&search%5Bsex%5D=%25&search%5Bnation%5D=%25&search_sort=name&event=I Basically, the query to the system's database is encoded in the URL, with fields either set to blank, or set to some value. Typically, we want to loop over the rider number (to get a "dump" of the database), but also might want to be crafty and check whether the rider is a male or a female, or even splice and dice the data including country of registration, that sort of thing.
In the following example, we split the URL field in two terms: a first term that is common to all queries, and can be thought of as the prefix, and an extra term that can be used to include different query terms, the suffix. In the middle, the rider number sits. To compose the URL then, we concatenate the prefix url1, the rider number and the suffix url_search.
We can loop over rider numbers, and add a nested loop that will request a given rider number and a particular sex. If the returned HTML contains the string No results found', it means that that particular rider will have to be of the oppossite sex. If we don't get this string, we can proceed to using BeautifulSoup to harvest the data.
In this particular case, we select all the td (table datum) elements in the page. For simplicity (and "upon inspection"), fields 13, 15 and 21 contain the name, the final distance and final time (you can get all the other fields in a similar fashion). We just build a string and and write it out to a file.
url1 = 'http://results.prudentialridelondon.co.uk/2013/?index.html?num_results=100&pid=search&search[start_no]='
url_search = { 'men': '&search[sex]=M&search[nation]=%&search_sort=name&event=I', \
'women': '&search[sex]=W&search[nation]=%&search_sort=name&event=I' }
fps = { 'men': open ("bike_ride_men.csv", 'w' ), \
'women': open("bike_ride_women.csv", 'w' ) }
for rider_no in xrange(3000,5001):
for sex in ["men", "women"]:
r = requests.get( url1 + "%d"%rider_no + url_search[sex])
html = r.text
if html.find ( "No results found.") < 0:
the_sex = sex
tree = BeautifulSoup( html )
stringo = "%d; " % rider_no
for i, s in enumerate( tree.findAll( "td") ):
if i == 12:
stringo += "'%s'; " % s.find("a").contents[0]
elif i == 14:
stringo += "%s; " % s.contents[0].split()[0]
elif i == 20:
stringo += "%s" % s.contents[0]
stringo += "\n"
fps[sex].write ( stringo.encode('utf-8') )
fps[sex].flush()
break
for q in fps.iterkeys():
fps[q].close()
Playing around with the data
So the previous process takes a while for retrieving up to 2000 riders. We have saved the data to disk, so let's have a little play around!
First, we need a function to conver the hours, minutes and seconds to minutes. In some cases, if the field is empty, we return the value -1 to indicate no data. A simple function like hhmmsss_to_mins below does the job well and is easy to follow:
def hhmmss_to_mins ( hhmmss ):
try:
hh, mm, ss = hhmmss.split ( ":" )
return float(hh)*60. + float(mm) + float(ss)/60.
except ValueError:
return -1
Now, let's load up the data we conveniently saved up beforehand as a CSV file (lesser mortals would be reaching for Excel here, but we know better!). We only really need columns 3 and 4 (unless you are looking for your name, or are curious about somebody else). np.loadtxt allows us to set delimiters, to only deal with two columns, and also to apply a converter to column 4 (that converts the hours, minutes and seconds to minutes using hhmmss_to_mins. We also have split the data into ladies and gentlemen, so we can load up each population individually.
blokes = np.loadtxt("bike_ride_men.csv", delimiter=";", usecols=[2,3], converters={3:hhmmss_to_mins})
birds = np.loadtxt("bike_ride_women.csv", delimiter=";", usecols=[2,3], converters={3:hhmmss_to_mins})
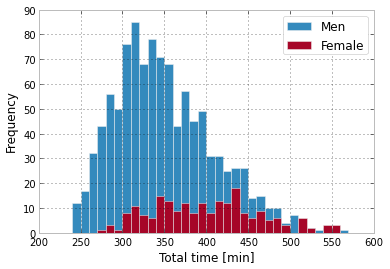
So far so good, why don't we just plot some histograms? Let's bin the data in 10minute arrival intervals
plt.hist ( blokes[blokes[:,1] > 0, 1], bins= np.arange(200,600,10), label="Men" )
plt.hist ( birds[birds[:,1] > 0, 1], bins= np.arange(200,600,10), label="Female" )
plt.legend(loc='best')
plt.xlabel("Total time [min]")
The IPython workbook
If you fancy, you can get the IPython notebook from wakari here: https://www.wakari.io/sharing/bundle/jgomezdans/BicycleBicycle. Feel free to play with the code!